BIGKinds LAB
KPF-BERT
- HOME
- 소개
- KPF-BERT
- 자연어 처리(NLP) 기술
- BERT 언어 모델
- 한국언론진흥재단 KPF-BERT
자연어 처리

인공지능의 한 분야인 자연어처리는 우리가 일상생활에서 사용하는 한국어, 영어, 속어 등의 자연어를 컴퓨터가 처리할 수 있도록 하는 기술로, 딥러닝 알고리즘을 활용하여 문서 분류, 문서 생성, 질의응답, 기계 번역 등을 수행한다.
- 기존 온톨로지˚ 기반 기술에서 인간의 개입을 최소화하고 데이터 기반 학습을 통해 스스로 언어를 이해하게 하는 워드 임베딩˚ 방식으로 전환
(Ontology)
(Word Embedding)
- GPT :
문장의 시작부터 순차적으로 계산하는 일방향 언어모델로, 이전 단어들이 주어졌을 때 다음 단어가 무엇인지 맞춤,
새로운 문장을 생성하는 데 유용
- BERT :
단어의 앞뒤 문맥을 모두 살피는 양방향 언어모델로, 문장 중간에 빈칸을 만들고 해당 빈칸에 어떤 단어가 적절한지 맞춤,
문장 의미를 추출하는 데 유용
자연어 처리 임베딩 기술

자연어 처리를 위해서는 텍스트를 컴퓨터가 이해할 수 있도록 숫자로 바꾸는 작업이 필요한다. 사람은 문장에서 단어가 쓰인 의미를 문맥을 통해 구분할 수 있지만, 기계가 이해할 수 있도록 단어를 0과 1의 수치로 표현하는 방법을 "벡터화(Vectorization) 또는 임베딩(Embedding)" 이라고 한다. 임베딩은 전체 단어들 간의 관계에 맞춰 해당 단어의 특성을 갖는 벡터로 바꿔주므로 단어들 사이의 유사도를 계산하는 기법이다. 이러한 유사도 계산을 통해 단어 간의 의미적 · 문법적 관계를 파악해낼 수 있다. 예를들어, "아들-딸" 사이의 관계와 "소년-소녀" 사이의 의미 차이가 임베딩에 함축되어 있으면 좋은 임베딩이라 할 수 있다. 임베딩 기법의 발전 흐름과 종류는 통계적 기반과 뉴럴 네트워크 기반으로 나눌 수 있고 단어수준과 문장수준의 임베딩 기법으로 구분할 수 있다.
자연어 처리 임베딩 기술의 흐름과 종류

임베딩 초기 기법은 통계적 기반을 중심으로 말뭉치(Corpus)˚ 의 통계량을 직접적으로 활용하였다.
대표적으로 잠재 의미 분석(Latent Semantic Analysis:LSA)은 단어 사용 빈도 등 말뭉치의 통계량 정보가 들어 있는 행렬에 특이값 분해 등
수학적 기법을 적용해 행렬에 속한 벡터들의 차원을 축소하는 방법이다. 여기서 차원축소를 통해 얻은 행렬을 기존의 행렬과 비교했을 때
단어를 기준으로 했다면 단어 수준 임베딩, 문서를 기준으로 했다면 문서 임베딩이 된다. 이러한 잠재 의미 분석 수행 대상 행렬에는 Term-Document, TF-IDF, One-hot Encoding 등이 있다.
컴퓨터의 발달로 말뭉치 분석이 용이해졌으며 분석의 정확성을 위해 해당 자연언어를 형태소 분석하는 경우가 많다.
확률/통계적 기법과 시계열적인 접근으로 전체를 파악한다. 언어의 빈도와 분포를 확인할 수 있는 자료이며,
현대 언어학 연구에 필수적인 자료이다.

워드 임베딩의 역사는 인공 망을 이용하여 주변 단어의 단어 등장 확률을 예측한 Neural Probabilistic Language Model(NPLM)이 발표된 이후부터 Word2Vec → FastText → ELMO → BERT 기법으로 발전하고 있다. 가장 최신의 언어분석 기법인 BERT는 다른 언어분석 기법들에 비해 임베딩 결과에서 우수한 성능을 보이고 있다. 이는 기존의 임베딩은 문장에서 단어를 순차적으로 입력받고 다음 단어를 예측하는 일방향(uni-directional)이지만 BERT는 문장 전체를 입력받고 단어를 예측하고 양방향(bi-directional) 학습이 가능하기 때문이다. 이러한 Neural Network 구조의 유연성과 풍부한 표현력으로 자연어의 문맥을 상당 부분 학습할 수 있고 높은 정확도를 보이고 있다.

단어 수준의 임베딩은 신경망을 이용하여 텍스트를 변환하는 것이 가장 큰 특징으로 단어가 주어지면 그 단어와 주변 단어가 동시에 일어날 확률을 구하므로 단어의 의미를 수치화할 수 있다. 임베딩 기술은 2017년 이전까지 대부분 단어 수준의 모델로 개발되어졌다. 단어 수준의 벡터 표현은 텍스트를 수치화한 벡터 형태로 표현하는 것이다. 이는 비슷한 의미를 가진 단어는 크기와 방향에 유사성을 가지는 경향이 있을 것이라는 가정이 핵심이다. 이러한 단어 임베딩은 문장의 유사도를 나타내는데 효율적이라는 사실이 증명되어 자연어 처리를 위한 딥러닝 모델적용 시 첫 번째 데이터 처리 레이어에서 자주 활용된다. 단어 수준의 임베딩 기법에는 Word2Vec, GloVe, FastText 등이 있다.

문장 수준의 임베딩은 2018년 초에 ELMo(Embedding from Language Models)가 발표된 이후 주목받기 시작했다. 이는 개별 단어가 아닌
단어 Sequence 전체의 문맥적 의미를 함축하기 때문에 단어 임베딩 기법보다 Transfer Learning 효과가 좋은 것으로 알려져 있다.
또한, 단어 수준 임베딩의 단점인 동음이의어도 문장수준 임베딩 기법을 사용하면 분리해서 이해할 수 있다.
문장 수준의 임베딩 기법에는 BERT, GPT 등이 있다. BERT(Bidirectional Encoder Representations from Transformer)는
2018년 구글의 Jacob Devlin과 그의 동료가 함께 만들었다. 이 모델은 최근까지 딥러닝 모델을 적용한 모든 자연어 처리 분야에서 좋은 성능을
보이고 있는 범용 언어 모델이다. BERT는 사전학습(pre-trained) 모델로서, 특정 과제(task)를 하기 전 사전훈련 임베딩을 실시하므로
기존의 임베딩 기술보다 과제의 성능을 더욱 향상시킬 수 있는 모델로 관심받고 있다. BERT를 적용한 모델링 과정을 살펴보면 Pre-trained는
비지도 학습(Unsupervised Learning) 방식으로 진행되고 대량의 말뭉치를 인코드(Encoder)가 임베딩하고, 이를 트랜스퍼(Transfer)하여
Fine-tuning을 통해 목적에 맞는 학습을 수행하여 과업을 수행하는 것이 특징이다. 또 다른 BERT의 특징은 양방향 모델을 적용하여
문장의 앞과 뒤의 문맥을 고려하는 것으로 이전보다 높은 정확도를 나타낸다.
BERT 정의

BERT(Bidirectional Encoder Representations from Transformers)는 2018년 구글이 공개한 사전 훈련된 언어 모델로,
자연어 처리(Natural Language Processing) 분야에서 사용되는 딥러닝 모델이다.
트랜스포머(Transformer)

BERT의 줄임말을 직역하면 다음과 같다.
"Transformers로 부터의 양방향(Bidirectional) Encoder 표현(Representations)"
BERT의 T는 트랜스포머(Transformer)로, 2017년 구글이 발표한
"Attention is All You Need" 라는 논문에서 처음 소개되었다.
트랜스포머 모델은 딥러닝 모델의 한 종류이다.
논문의 핵심인 Attention은 "어떤 하나의 기능을 담당하는 함수라는 의미로"
Seq2Seq, 인코더/디코더,RNN등의 단계를 거친다.
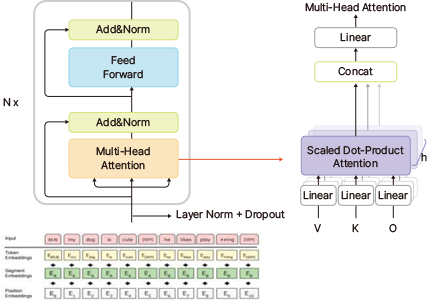
트랜스포머 모델에는 인코더(Encoder) 라는 기능이 존재하는데,
이 기능을 사용하여 만든 것이 BERT이다. 기본적으로 BERT는 인코더를
최대 24개의 층으로 겹겹이 쌓아올렸으며, 이는 대규모의 텍스트를
단어의 의미, 문장에서의 의존적, 구문적 역할을 재현할 수 있게 한다.
양방향 표현(Bidirectional Representations)

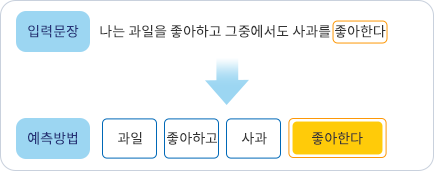
기존의 NLP 모델들은 학습을 시킬 때, 좌에서 우로 또는 우에서 좌의 방향으로 입력 데이터를 학습시켰다. 이를 일방향성(Unidirectional)이라고 한다
즉, 좌에서 우의 방향으로 데이터를 학습시키는 방법은, 모델이 입력 데이터로 들어가는 문장이 있을 때, 문장앞의 n개의 단어를 이용하여 그뒤에 나올 단어를 예측한다.

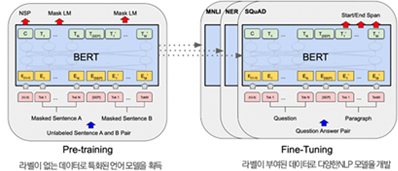
그러나 BERT는 구글이 직접 개발한 NSP 방식(Next Sentence Prediction)과 MLM(Masked Language Model) 방식으로 양방향성으로 학습시킨다.
즉, 입력된 문장의 전체에서 n개의 단어를 둘러보고 유추하는 방식이다.

KPF-BERT

KPF-BERT는 한국언론진흥재단에서 "언론사를 위한 언어정보 자원 개발" 사업의 결과물로 구축된 한국형 표준 뉴스 기사 인공지능 언어 모델이다.
구글의 BERT를 기반으로 한국언론진흥재단이 보유한 빅카인즈 기사 데이터를 활용해 Pre-training 시켰으며 2000년부터 2021년 8월까지 빅카인즈 기사
약 4,000만 건(20년치 8,158만 건 중 1차 정제 후 약 4,000만 건)을 학습해 언론사 및 뉴스 기사 활용 기술에 최적화되도록 개발되었다.

fine-tuning은 목적과 방법에 따라 다음 3가지 형태가 있다.
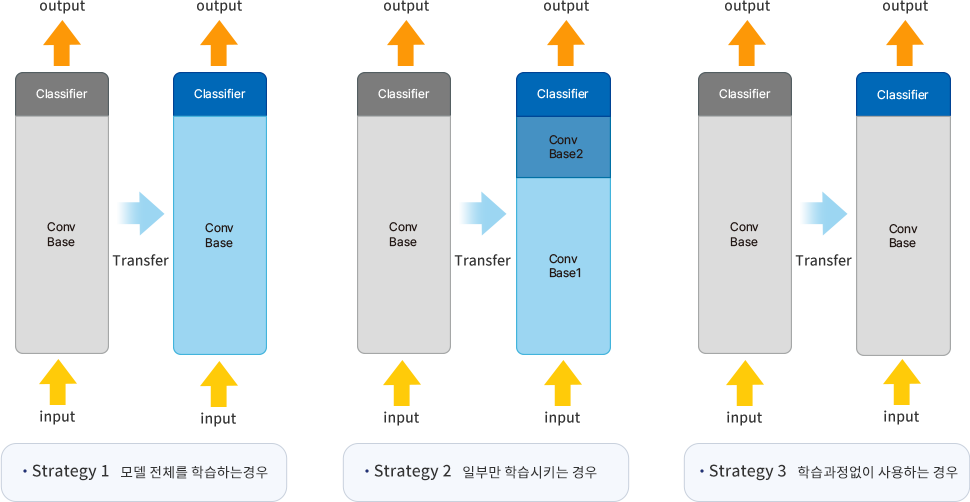
KPF-BERT는 Strategy 2 : 일부만 학습시키는 경우의 방식으로 서비스 할 수 있는 학습데이터(라벨링된 데이터)를 사용하여 학습하였다.

| 모델 | 모델 소개 |
|---|---|
|
KPF-BERT SUM |
KPF-BERT Text Summarization 으로 한국어 문장의 요약추출을 구현한 한국어 요약 모델이다. |
|
KPF-SBERT |
KPF-BERT Sentence BERT로 문장단위 Embedding을 통하여 빠르고 효율적으로 의미비교 등의 작업에 활용된다. |
|
KPF-SBERT |
KPF-SBERT HDBSCAN Clustering 으로 KPF-SBERT를 활용하여 군집 분류에서 높은 성능을 기록한 HDBSCAN을 이용한다. |

KPF-BERT의 학습 과정은 말뭉치 준비, 모델 학습, 성능 평가의 순서로 이루어진다.
1
KPF-BERT 학습
말뭉치 준비
KPF-BERT의 단어사전 제작을 위해 모두의 말뭉치 원시 데이터, 웹페이지 저장소 Common Crawl의 한국어 데이터 등 총 5개의 말뭉치 범위의 데이터 약 20GB의 데이터가 샘플링 된다. 또한 토크나이저 구축을 위해 AI 플랫폼 huggingface 라이브러리를 이용한 BERT Word Piece용 단어사전이 적용되었다. 이렇게 모든 말뭉치를 사용하여 단어 사이즈 32,000 개의 단어 사전이 제작되었다.
| 데이터 준비 | 내용 |
|---|---|
|
빅카인즈 |
빅카인즈 뉴스 기사 데이터 추출 작업 |
|
국립국어원 |
구어 말뭉치 |
|
Common Crawl |
정형화 되지 않은 표현이나 이모티콘들 |
| 토크나이저 파일 결과 | |
|---|---|
|
toknizer_config.json |
{ |
|
생성된 Vocab.txt 파일 |
파일 사이즈 276kb, 36440 lines (36440 sloc) |
|
토크나이저 사용법 |
pip3 install torch >= 1.4.0 |
2
성능 평가 결과
KPF-BERT 성능 평가를 위한 평가 파이프라인으로 네이버 영화리뷰 감정분석, KLUE 벤치마킹, KorQuad 벤치마킹이 적용되었다.
모델은 총 5개의 모델에 대하여 평가 작업이 수행 되었다.
| 구분 | 성능 평가 |
|---|---|
|
NSMC |
Naver Sentiment Movie Corpus / 네이버 영화리뷰 감정분석 |
|
KLUE |
Korean Language Understanding Evaluation / 한국어 이해 평가 |
|
KorQuAD |
The Korean Question Answering Dataset / 한국어 MRC 데이터 셋 |
| 구분 | NSMC | KLUE-NLI | KLUE-STS | KorQuaD v1 | KLUE MRC |
|---|---|---|---|---|---|
|
데이터 규격 |
영화리뷰 |
자연어 추론 |
문장 의미적 |
기계 독해 |
기계 독해 |
|
평가방법 |
Accuracy |
Accuracy |
Person |
Exact Match |
Exact Match |
|
KPF-BERT |
91.29% |
87.67% |
92.95% |
86.42% |
69.51% |
|
KLUE BERT |
90.62% |
81.33% |
91.14% |
83.84% |
61.91% |
|
KorBERT |
90.46% |
80.56% |
89.52% |
20.11% |
30.56% |
|
KoBERT |
89.92% |
79.53% |
86.17% |
16.85% |
28.56% |
|
BERT Base |
87.33% |
73.30% |
85.66% |
69.10% |
44.58% |